
这是我毕业项目的主页。项目的内容是“人们在社交网络上,更倾向于表达怎样的情绪”。
项目背景介绍
- 项目的起点是在知乎上看到了这篇相对于现实,人们更倾向于在社交网络中表达负面情绪?
- 这是我人生中第一次尝试为开源做贡献,项目所有源码、数据开源,尽最大的可能帮助想要学习、尝试或者对我的项目感兴趣的人。
- 这个项目的所用语言为python,“这辆老爷车有很多RPG之类的重武器,并且很好用”,我喜欢python的简洁。
- 项目的内容包括但不限于:爬虫,中文分词,统计及机器学习,数据可视化。
项目内容简介
- 从微博(因为字数有限制)爬取大学生(安徽医科大学)学生所发的状态,去除掉转发和广告之类的信;(50%)
- 标记20%的数据,1或者0(乐观或者悲观);(0 %)
- 根据中文分词,用navie bayes算出所有数据的label ; (0%)
- 数据可视化;(0%)
项目可能出现的问题
根据某学霸提醒,项目中可能有的问题:1.从数据到结论(如何更好的解释结果);2.结论单薄,可以尝试抽取部分小的数据集得到小结论。
Update 2015.03.23
感谢 Morgan Zhang 的帮助。 目前完成的对微博用户的爬取(只有用户信息)。
- 该爬虫用了多线程机制,程序中有time.sleep(1)。
- 数据库用的是MySQL。
- 爬的久了还是会封号,不过因为sleep(1)后好像能爬的更久了,难道是幻觉?
Update 2015.03.27
感谢王冠同学的帮助,他说“为什么不存两个表呢”,解决了我蛋疼很久的问题。
话不多说。先上图:
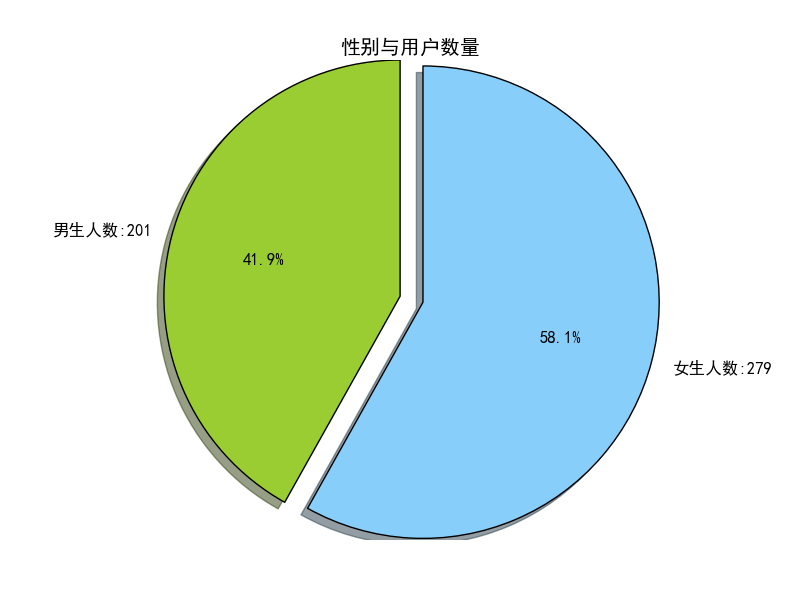
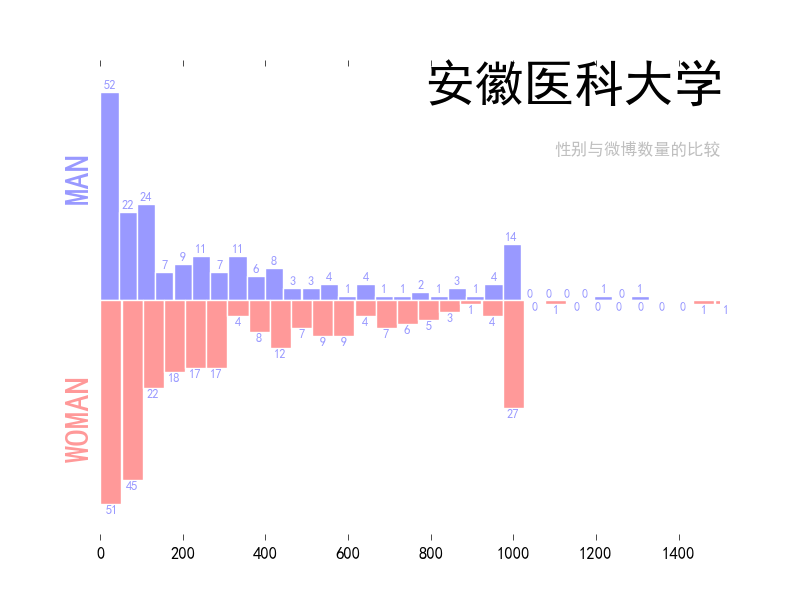
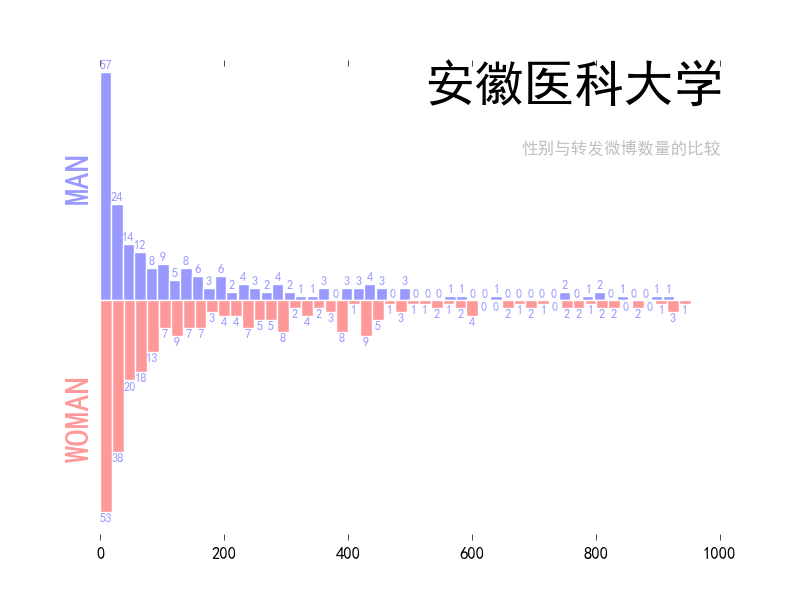
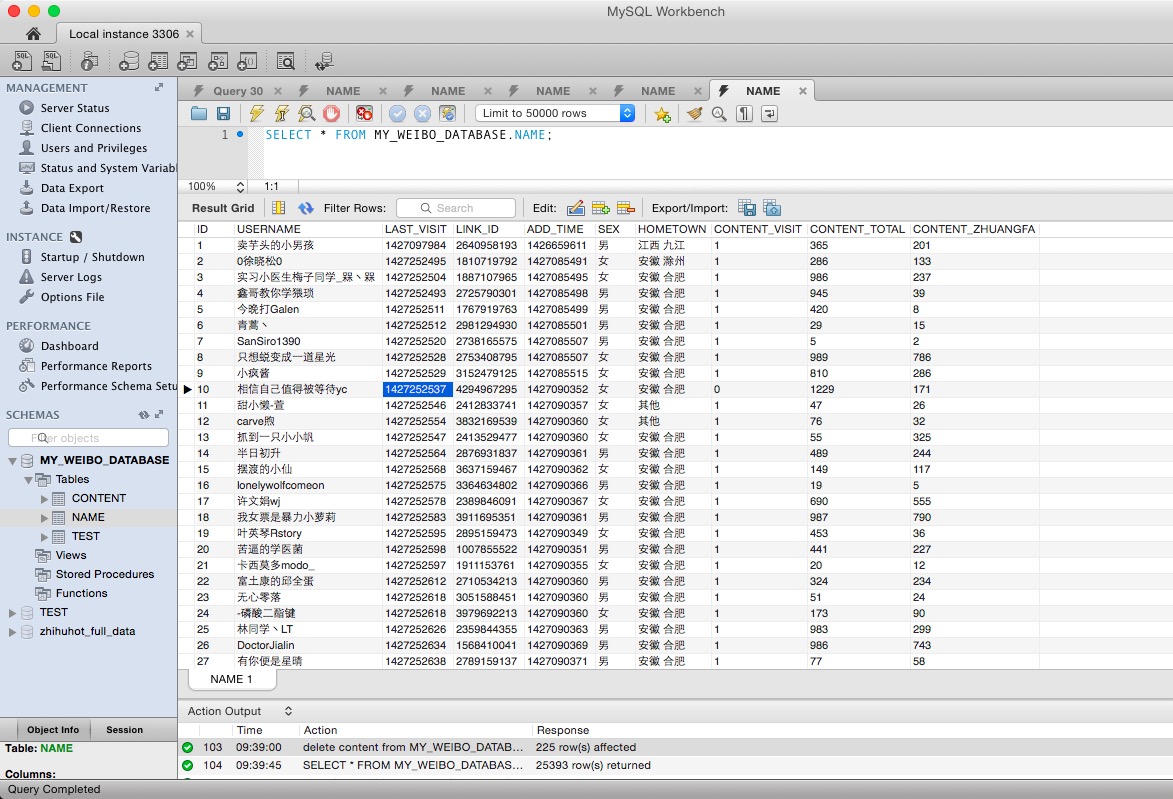
总算有一点成果了。我改了原来的表,加了两列,分别是每个用户所发的微博数量和转发的数量。
然后我新建了一张表,用来存放每条有用的微博信息。如下图。
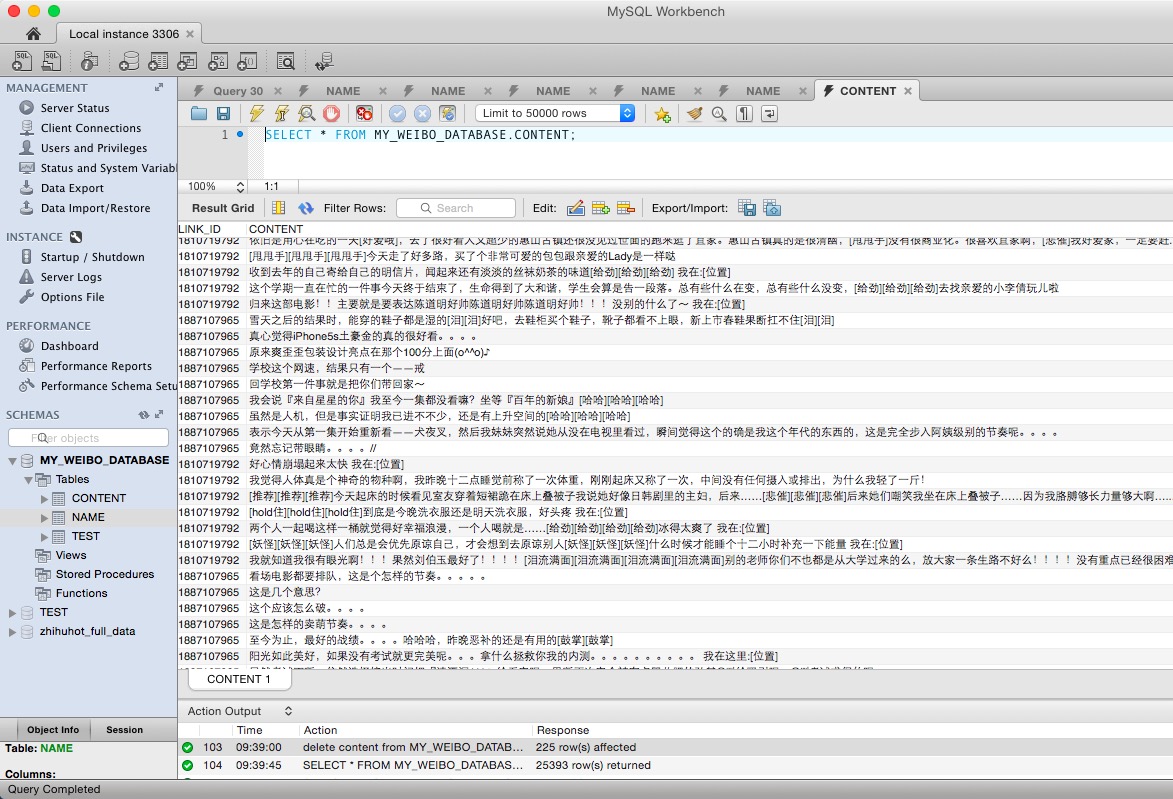
现在大概爬了500+的用户,因为爬的太快会被冻结账号,所以现在只能放慢速度。
还有很多东西没想好怎么弄,过两天可以先把data clean和中文分词做好了。诚邀学统计的学数学的学机器学习的同学,接下来我真的不知道怎么弄了。
这里有一堆纯文本文件,希望能一起发现里面好玩的东西。
谢谢琛涛,我希望更多的人去了解python,运行我的程序,把你的学校的结果给我。
最后谢谢fork和star我的所有人,我这么不要脸求star,是为了理想。